Wann kann ein A/B-Test beendet werden?


Eine der größten Stolperfallen im A/B-Testing besteht darin, einen Test zu früh zu beenden. Doch wann ist der richtige Zeitpunkt, um einen Test abzuschließen? Eine allgemein gültige Antwort gibt es nicht.
Wichtig ist, die zentralen Konzepte und Faktoren zu kennen, die bei der Entscheidung über das Testende eine Rolle spielen – unabhängig davon, ob mit der Bayes’schen oder der Frequentist-Methode gearbeitet wird.
Welche Elemente beeinflussen den richtigen Zeitpunkt für das Testende?
Mehrere Parameter haben direkten Einfluss darauf, wann ein A/B-Test beendet werden kann und sollten deshalb stets berücksichtigt werden:
- Konfidenzniveau
- Stichprobengröße
- Testdauer
- Datenvariabilität
Keiner dieser Faktoren allein ist Grund genug, einen Test abzubrechen. Doch das Verständnis dieser Konzepte hilft, fundierte Entscheidungen darüber zu treffen, wann ein Test wirklich abgeschlossen werden sollte.
Konfidenzniveau
Ein Konfidenzniveau unter 95 % sollte nicht akzeptiert werden. Doch Vorsicht: Das bedeutet nicht automatisch, dass ein Test sofort beendet werden sollte, sobald 95 % erreicht sind.
Wenn ein A/B-Testing-Tool anzeigt: „Die Variante hat x % Wahrscheinlichkeit, besser als die Kontrollversion abzuschneiden“, bezieht sich das auf das Konfidenzniveau. Anders gesagt: Es besteht ein Risiko von 5 % (ein Zwanzigstel), dass die gemessenen Ergebnisse rein zufällig zustande kommen.
Ein Wert von 80 % wirkt auf den ersten Blick solide, doch wer den Test bei diesem Niveau stoppt, erhöht das Fehlerrisiko dramatisch: Statt 5 % beträgt es nun 20 %. Ziel ist nicht nur ein „gutes“ Ergebnis, sondern ein statistisch belastbares Resultat — schließlich stehen Zeit, Ressourcen und Budget auf dem Spiel.
Heißt das, dass ein Test bei 95 % todsicher richtig liegt? Nein. Das Konfidenzniveau ist notwendig, aber nicht ausreichend, um das Testende zu bestimmen. Bei einem unechten Test (A/A-Test), bei dem zwei identische Varianten gegeneinander laufen, liegt die Wahrscheinlichkeit, zufällig 95 % zu erreichen, bei etwa 70 %. Das zeigt: Das Konfidenzniveau allein reicht nicht aus, um den Test zu beenden.
Stichprobengröße
Für valide Ergebnisse braucht es eine repräsentative Stichprobe aller Besucher:innen — es sei denn, der Test richtet sich gezielt an ein bestimmtes Segment. Die Stichprobe muss groß genug sein, um nicht von natürlicher Datenvariabilität verzerrt zu werden. Entscheidend ist, eine Nutzergruppe auszuwählen, deren Verhalten für die gesamte Audience steht.
Das setzt voraus, die eigenen Besucher:innen genau zu kennen. Vor jedem A/B-Test sollte daher eine gründliche Analyse der Traffic-Quellen und Zielgruppen erfolgen, zum Beispiel:
- Wie viele Besucher:innen kommen über Pay-per-Click, direkten Traffic, organische Suche oder E-Mail?
- Wie hoch ist der Anteil an wiederkehrenden vs. neuen Besucher:innen?
Da sich Traffic-Strukturen ständig verändern, lassen sich diese Daten nie zu 100 % exakt bestimmen. Umso wichtiger ist es, sicherzustellen, dass die Stichprobe proportional und repräsentativ für den gesamten Website-Traffic ist.
Achtung bei zu kleinen Stichproben: Je kleiner die Stichprobe, desto stärker können Sonderfälle und Ausreißer die Ergebnisse beeinflussen. Kleine Stichproben führen zu größeren Schwankungen in den Messwerten.
Ein einfaches Beispiel: Wir werfen eine Münze zehn Mal und wissen, dass die „echte“ Wahrscheinlichkeit für Kopf bei 50 % liegt. Machen wir fünf Serien mit je zehn Würfen, wird deutlich, wie stark kleine Stichproben schwanken können.

Die Ergebnisse schwanken zwischen 20 und 80 %. 2. Gleiches Experiment, aber wir werfen die Münze nicht 10, sondern 100 Mal.
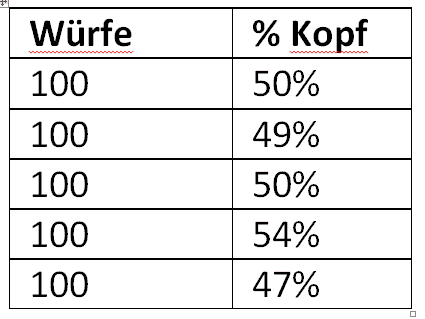
Bei 100 Würfen schwanken die Ergebnisse nur noch zwischen 47 % und 54 %. Je größer also die Stichprobe, desto näher kommt man dem „echten“ Wert.
Noch klarer wird das an einem praktischen Beispiel: Angenommen, ein A/B-Test läuft und bereits am ersten Tag scheint eine Siegervariante festzustehen. Der Grund: An diesem Tag wurde ein Newsletter verschickt und ein Großteil der Besucher:innen sind bereits bestehende Kund:innen. Diese Gruppe reagiert naturgemäß positiver, weil sie der Marke vertraut.
Würde der Test jetzt beendet, wären die Ergebnisse verfälscht — selbst dann, wenn das Konfidenzniveau bereits bei über 95 % liegt.
Wie groß sollte die Stichprobe sein?
Es gibt leider keine magische Zahl, die all Ihre Probleme löst. Alles hängt davon ab, wie groß die Verbesserung, die Sie suchen, sein soll. Je größer die Verbesserung ausfallen soll, desto kleiner kann Ihre Stichprobe sein. Aber selbst wenn sie Google-artigen Traffic haben, ist das an sich kein Grund, den Test zu stoppen. Wir kommen später darauf zurück. Ein Punkt gilt für alle Methoden: Je mehr Daten Sie sammeln, desto akkurater und vertrauenswürdiger sind Ihre Ergebnisse.
Es gibt leider keine magische Zahl, die für alle A/B-Tests gilt. Wie groß die Stichprobe sein muss, hängt immer davon ab, wie stark die angestrebte Verbesserung ausfallen soll. Je größer die erwartete Veränderung, desto kleiner kann die benötigte Stichprobe sein.
Selbst wenn eine Website extrem hohen Traffic hat, ist das kein Grund, einen Test vorschnell zu beenden. Ein Grundsatz gilt unabhängig von der Methode: Je mehr Daten gesammelt werden, desto verlässlicher und aussagekräftiger sind die Ergebnisse.
Das konkrete Vorgehen hängt außerdem von der Statistik-Methode ab, die das eingesetzte Tool verwendet. Unser Rat für alle, die mit der Frequentist-Methode arbeiten:
- Nutze einen Sample Size Calculator (z. B. den von Kameleoon). So erhält man eine klare Zahl, ohne selbst rechnen zu müssen, und vermeidet es, den Test zu früh zu stoppen.
- Gib dazu einfach die aktuelle Conversion Rate der Seite und die minimal angestrebte Verbesserung ein.
- Empfehlenswert sind mindestens 300 Conversions pro Variante, bevor überhaupt über ein Testende nachgedacht wird. Wenn der Traffic es zulässt, sind 1.000 Conversions pro Variante ideal. Grundsätzlich gilt: je mehr, desto besser.
Eine kleine Stichprobe kann nur dann ausreichen, wenn der Unterschied zwischen Kontrollversion und Variante wirklich erheblich ist. Aber Vorsicht:
Selbst wenn der Traffic hoch ist und die Stichprobe groß genug erscheint, reicht ein Konfidenzniveau von 95 % allein immer noch nicht aus, um den Test vorzeitig zu beenden.
Testdauer
A/B-Tests sollten immer volle Wochen abdecken — empfohlen werden mindestens 2 bis 3 Wochen. Wenn möglich, ist es sinnvoll, die Laufzeit an einen oder sogar zwei komplette Geschäftszyklen anzupassen.
Warum das wichtig ist: Das Nutzerverhalten schwankt stark je nach Wochentag und wird von externen Faktoren beeinflusst — etwa vom Wetter, aktuellen Nachrichten, saisonalen Verkäufen oder besonderen Ereignissen. Das gilt auch für die Conversion Rate.
Ein einfacher Selbsttest zeigt das deutlich: Wer die Conversion einmal pro Tag misst, wird feststellen, wie stark die Ergebnisse von einem Tag zum anderen schwanken. Um diese Schwankungen auszugleichen, sollten Tests daher über ganze Wochen und vollständige Zyklen laufen.
Wenn eine Verlängerung nötig wird, dann ebenfalls immer um eine ganze Woche. Ein Test, der an einem Donnerstag startet, sollte also auch an einem Donnerstag enden. So lassen sich Verzerrungen durch unvollständige Zeiträume vermeiden und die Datenbasis bleibt konsistent.
Datenvariabilität
Solange Konfidenzniveau und Conversion Rates der Varianten stark schwanken, sollte ein A/B-Test nicht beendet werden. Zwei wichtige Effekte müssen dabei bedacht werden:
- Neuigkeitseffekt: Nutzer:innen reagieren oft zunächst nur deshalb positiv oder negativ, weil etwas neu ist. Dieser Effekt flacht mit der Zeit ab.
- Regression zum Mittelwert: Je mehr Daten gesammelt werden, desto stabiler und näher am „echten“ Wert liegen die Ergebnisse. Gerade zu Beginn können wenige Sonderfälle die Zahlen stark verzerren.
Diese Punkte zeigen: Das Konfidenzniveau allein ist kein ausreichendes Kriterium, um einen Test zu beenden. Es sollte mehrfach die 95-%-Marke erreichen, bevor über das Testende entschieden wird. Warten lohnt sich, bis die Kurve des Konfidenzniveaus sichtbar abflacht und stabil bleibt.
Das Gleiche gilt für die Conversion Rates der Varianten. Erst wenn die Schwankungen in Bezug auf die aktuelle Situation und die Werte selbst unbedeutend werden, sind belastbare Aussagen möglich.
Beispiel:
- Version A: Conversion Rate 18,4 % ± 1,2 %
- Version B: Conversion Rate 14,7 % ± 0,8 %
Das bedeutet, dass die tatsächliche Conversion Rate von Version A zwischen 17,2 % und 19,6 % liegt, und die von Version B zwischen 13,9 % und 15,5 %. Erst wenn sich solche Intervalle stabilisieren und kaum noch verändern, ist der richtige Zeitpunkt gekommen, den Test zu beenden.
Wenn sich die Konfidenzintervalle der Varianten überschneiden, sollte der Test auf jeden Fall weiterlaufen. Mit zunehmender Testdauer werden die Intervalle kleiner, die Messwerte stabiler und die Ergebnisse präziser.
Am besten ist es, die Resultate vor Testende gar nicht anzusehen. So entsteht gar nicht erst die Versuchung, den Test vorschnell zu stoppen und dadurch unzuverlässige oder verzerrte Daten zu riskieren.
Voraussetzungen für ein verlässliches Testende
Um einen A/B-Test sicher beenden zu können, braucht es: Der Test sollte erst beendet werden, wenn alle diese Bedingungen erfüllt sind. Wird vorher abgebrochen, besteht das Risiko, Zeit und Geld zu verlieren und falsche Entscheidungen zu treffen.
- ein Konfidenzniveau von mindestens 95 %,
- eine repräsentative Stichprobe der gesamten Audience,
- eine ausreichende Testdauer,
- sowie die Stabilisierung von Conversion Rates und Konfidenzniveau
Der Test sollte erst beendet werden, wenn alle diese Bedingungen erfüllt sind. Wird vorher abgebrochen, besteht das Risiko, Zeit und Geld zu verlieren und falsche Entscheidungen zu treffen.




