Tester en production : la meilleure façon de réduire les risques de mise en production


Le test en production (ou « shift-right testing ») est l'une des approches les plus efficaces pour sécuriser les mises en production.
Pourquoi ? Parce qu'il permet de détecter ce que les environnements de test ne révèlent pas toujours : comportements inattendus, cas limites, problèmes de performance à grande échelle ou encore réactions réelles des utilisateurs. Et tout cela de manière progressive, avec les garde-fous nécessaires pour limiter les risques.
Dans cet article, nous verrons ce qu'est le test en production, les différentes méthodes disponibles et la manière dont les équipes l'utilisent concrètement pour livrer plus sereinement.
Qu'est-ce qu’un test en production ?
Tester en production signifie exactement ce que son nom indique : valider un changement directement dans l'environnement de production.
Contrairement à une idée reçue, cette approche ne remplace pas les tests réalisés pendant le développement. Elle les complète.
Même les environnements de pré-production les mieux conçus ne parviennent jamais à reproduire parfaitement la réalité. Le trafic réel, les données de production, les comportements utilisateurs, les dépendances tierces ou encore les effets d'échelle créent des conditions impossibles à simuler intégralement.
En d'autres termes, la production est le seul environnement capable de fournir le contexte complet. C'est pourquoi les équipes les plus avancées y déplacent une partie de leurs validations.
Comment choisir la bonne stratégie de test en production ?
Le test en production ne repose pas sur une seule méthode. Il combine plusieurs approches : exécutions silencieuses en arrière-plan, déploiements progressifs ou expérimentations auprès des utilisateurs.
Le choix dépend généralement de trois critères :
- Le niveau de risque
- L'impact utilisateur
- Les objectifs métier
1. Niveau de risque
La première question à se poser est simple : quel est le risque en cas de problème ?
Pour les changements les plus sensibles, il est préférable de commencer sans exposition utilisateur. Les approches comme le dark launching ou le shadow testing permettent de valider le comportement d'un système dans des conditions réelles tout en restant invisibles pour les utilisateurs.
Prenons l'exemple d'un nouveau moteur de détection de fraude. Avant de lui permettre de bloquer de véritables transactions, il est plus prudent de l'exécuter en parallèle du système existant, d'observer ses décisions et de comparer ses résultats à ceux du modèle actuel.
Cette approche permet de confirmer sa précision avant toute exposition.
Pour cela, il est indispensable de disposer :
- D'une journalisation structurée pour comparer les prédictions aux résultats observés
- D'un traçage distribué pour suivre les temps de réponse
- De tableaux de bord permettant de surveiller les faux positifs et les faux négatifs
2. Impact utilisateur
Lorsque les utilisateurs sont directement exposés au changement, la stratégie doit évoluer.
Une modification purement back-end peut souvent être validée discrètement. En revanche, lorsqu'une évolution affecte l'interface, les performances ou le parcours utilisateur, l'enjeu devient autant fonctionnel qu'expérience utilisateur.
Dans ce contexte, les approches comme l'A/B testing ou la livraison progressive permettent de contrôler l'exposition tout en observant les comportements réels.
L'objectif n'est plus seulement de vérifier que le système fonctionne, mais de mesurer comment les utilisateurs réagissent.
Les éléments d'observabilité essentiels incluent :
- L'analyse en temps réel des interactions (clics, scrolls, abandons)
- Le suivi des événements clés du parcours
- Les analyses par segment d'utilisateurs
- Des alertes automatiques en cas de baisse des performances business
Avec l'AI Copilot de Kameleoon, par exemple, il est possible d'ajuster automatiquement l'exposition en fonction des KPI observés en temps réel.
3. Objectifs métier
Enfin, la manière de tester dépend du résultat recherché.
Si l'objectif est de valider une logique métier, une migration technique ou un comportement système, les méthodes silencieuses restent les plus adaptées.
En revanche, lorsqu'il s'agit d'améliorer l'engagement, la conversion ou la rétention, il devient nécessaire d'exposer des cohortes d'utilisateurs et de mesurer l'impact réel des changements.
Le succès ne se mesure alors plus uniquement à la stabilité technique, mais à la valeur générée pour l'entreprise.
Dans ce cas, les équipes s'appuient généralement sur :
- Le suivi des entonnoirs de conversion
- Les métriques d'engagement et de rétention
- Les analyses de significativité statistique
- Les tableaux de bord orientés objectifs métier
En réalité, les équipes combinent plusieurs approches
Le test en production consiste rarement à choisir une seule méthode.
Les organisations les plus matures les combinent.
Par exemple, une équipe peut :
- Exécuter un nouveau service en shadow testing.
- Déployer son modèle via un dark launch.
- Exposer progressivement la fonctionnalité grâce à un feature flag.
- Finalement mesurer son impact via un A/B test.
L'ensemble forme une stratégie cohérente qui permet de réduire les risques tout en accélérant les mises en production.
Les principales méthodes de test en production
Dark launching
Le dark launch consiste à déployer une fonctionnalité en production sans la rendre visible aux utilisateurs.
Le code s'exécute, génère des résultats et produit des métriques, mais reste masqué derrière un feature flag.
Cette approche permet de valider les performances et la stabilité dans des conditions réelles avant toute exposition.
Requis : feature flags, observabilité et outils de comparaison des résultats.
Shadow testing
Le shadow testing exécute un nouveau système en parallèle du système de production.
Une copie du trafic réel lui est envoyée afin de comparer ses résultats à ceux du système existant.
Les utilisateurs continuent d'utiliser la version actuelle, tandis que les écarts sont analysés en arrière-plan.
Requis : duplication du trafic, outils de comparaison et journalisation.
Canary rollout
Le déploiement canari consiste à exposer une nouvelle version à une faible part du trafic, généralement entre 1 % et 5 %.
Si les indicateurs restent conformes aux attentes, l'exposition est progressivement augmentée jusqu'au déploiement complet.
Requis : segmentation du trafic, supervision en temps réel et mécanismes de rollback.
Progressive delivery
La progressive delivery pousse encore plus loin le principe du canari.
L'augmentation du trafic est automatisée et pilotée par des seuils définis à l'avance : taux d'erreur, latence, disponibilité, etc.
Tant que les métriques restent conformes, l'exposition progresse automatiquement.
Requis : feature flags, observabilité et automatisation des règles de déploiement.
A/B testing
L'A/B testing vise avant tout l'optimisation.
Deux versions d'une expérience sont présentées à des groupes d'utilisateurs différents afin de mesurer leur impact sur des indicateurs tels que la conversion, la rétention ou l'engagement.
Contrairement aux autres méthodes de test en production, l'objectif n'est pas de valider la stabilité mais de déterminer quelle version génère les meilleurs résultats.
Requis : plateforme d'expérimentation et suivi statistique.
Blue-green deployment
Cette approche repose sur deux environnements de production identiques.
Une nouvelle version est déployée sur l'environnement secondaire, testée puis activée par simple bascule du trafic lorsqu'elle est validée.
Requis : infrastructure parallèle et répartiteur de charge.
Ring deployments
Les déploiements en anneaux permettent d'introduire progressivement une nouveauté auprès de groupes d'utilisateurs successifs :
- Équipes internes
- Bêta-testeurs
- Early adopters
- Ensemble des utilisateurs
Chaque étape sert de point de validation avant d'élargir l'exposition.
Requis : gestion des cohortes et processus de déploiement progressif.
Chaos engineering
Le chaos engineering consiste à provoquer volontairement des incidents contrôlés afin de vérifier la résilience du système.
L'objectif est de s'assurer qu'en cas de panne réelle, la plateforme continue de fonctionner de manière acceptable et se rétablit correctement.
Requis : outils d'injection de pannes, observabilité avancée et processus de gestion des incidents.
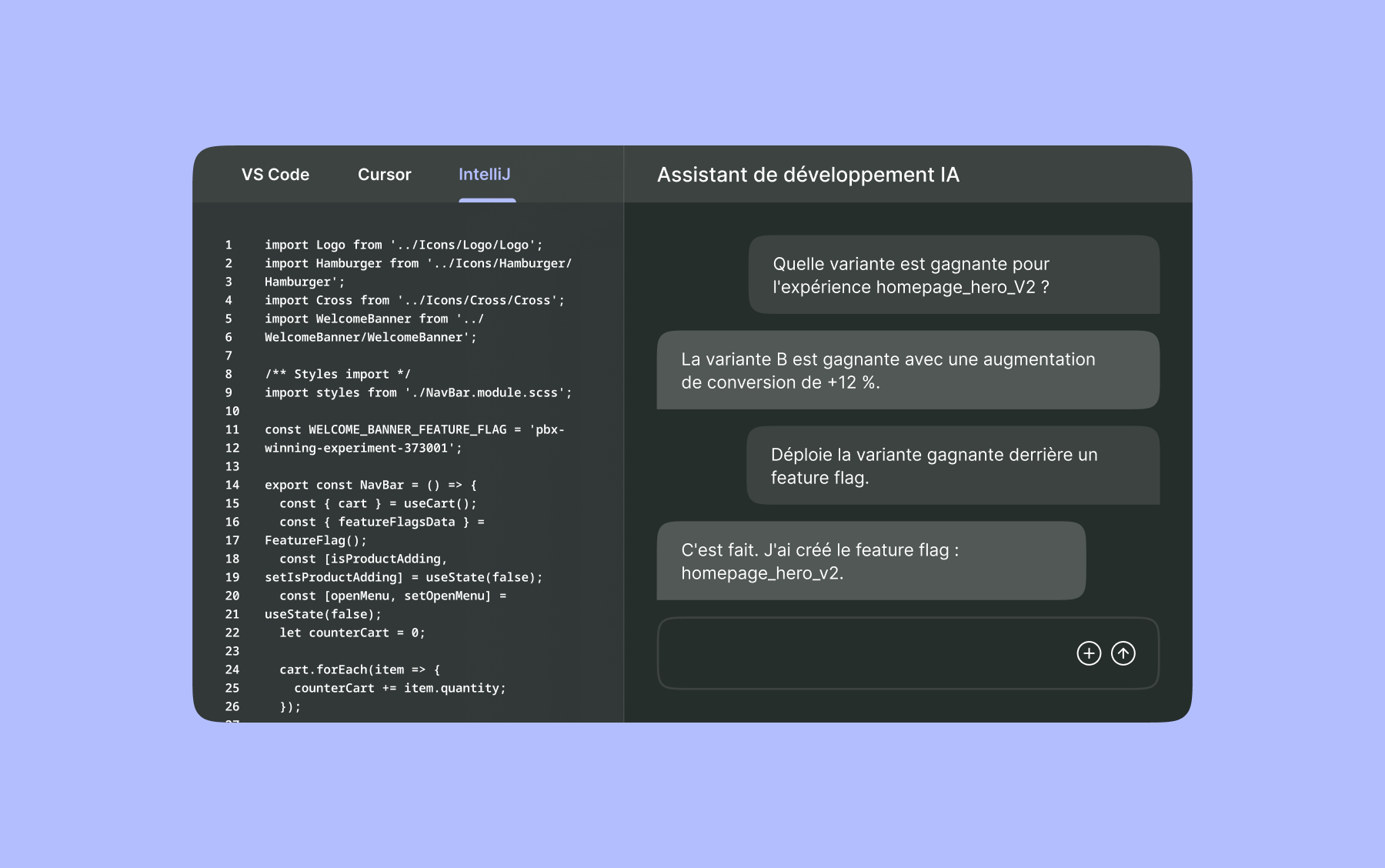
Les feature flags, pilier du test en production
Les feature flags sont devenus un composant central des stratégies de test en production.
Ils permettent de déployer du code indépendamment de sa mise à disposition aux utilisateurs.
Grâce aux feature flags, il devient possible de :
- Tester discrètement de nouveaux comportements en production
- Cibler des populations spécifiques
- Déployer progressivement une fonctionnalité
- Revenir en arrière instantanément
- Modifier le comportement d'un système sans redéploiement
Associés aux outils d'observabilité et d'expérimentation, ils transforment la production en environnement de validation contrôlé.
Comment démarrer ?
Le test en production est avant tout un changement de culture.
Il n'est pas nécessaire d'adopter toutes les pratiques dès le premier jour.
Commencez par identifier des cas à faible risque : un service back-end pouvant être exécuté en dark launch ou une fonctionnalité activée uniquement pour des utilisateurs internes.
Ensuite :
- Renforcez votre observabilité
- Mettez en place des déploiements progressifs
- Généralisez l'usage des feature flags
- Automatisez les mécanismes de rollback
Avec le temps, vous passerez d'une logique de réaction aux incidents à une démarche proactive de validation continue.
Qu'il s'agisse de valider des services techniques ou d'optimiser des parcours utilisateurs, le test en production permet d'améliorer simultanément la qualité, la rapidité de livraison et la confiance dans les mises en production.