
Google Optimize sunset, GA4 limitation, what if we have been looking at this from the wrong angle?

In February 2023, Google announced the depreciation of its A/B testing tool, Google Optimize. Although the news sent the industry into a panic, but, in my opinion, much of this was an overreaction. Here’s why.
Google Optimize lags behind many industry standards. Although it is set to be replaced by GA4 and Experimentation tools’ APIs, this requires an additional set of instruments (BigQuery & Looker) to perform as desired, making it a poor replacement.
Along with the Google Optimize sunset, Google also announced that it would replace Universal Analytics (UA) with Google Analytics 4 (GA4). The move to GA4 represents a larger paradigm shift from traditional marketing analytics platforms to product analytics.
GA4 offers features such as event-based tracking, a user-centric approach, and cross-device reporting. With event-based tracking, GA4 allows you to natively track specific user interactions on your website, such as button clicks, scrolls, or video plays, rather than just measuring page views and other session-based data. These changes position GA4 more in-line with product analytics tools compared to its predecessor, Universal Analytics.
However, GA4 has a steep learning curve for marketers, as well as limited reporting capabilities. Data must be exported into BigQuery and passed downstream to Google’s visualization studio, Looker, for deeper analysis. As a result, GA4 is no longer a “fit for all.”
The combination of several tools — GA4, BigQuery, and Looker — brings us to the third and last polemic: the modern data stack.
An introduction to the modern data stack
The modern data stack (MDS) is a set of tools that are used to collect, process, and analyze large volumes of data. If you’ve heard of Snowflake, Databricks, Fivetran, dbt or Dataiku, you’re familiar with the MDS.
These companies have raised hundreds of millions in venture capital with the promise of offering infinite ways to combine tools for the sake of the ideal data stack. Most importantly, they offer alternatives for companies that want to build a strong data ecosystem without being locked into Google.
The MDS, Universal Analytics sunset, and Google Optimize sunset all take place in a transforming landscape making them tightly linked.
Below, we’ll discuss the MDS in more detail — the reason for its rise, what it entails, and the potential implications for the experimentation industry.
The death of third-party data
The modern data stack came about as a result of many factors including the decrease in cost of cloud computing and cloud storage, the multiplication of tools generating silos, and advanced technological breakthroughs.
However, another significant catalyst in the rise of the MDS is the demise of third-party data due to Apple's ITP and regulations like GDPR and CCPA.
The death of third-party data means online businesses can no longer rely on data stored in a complex system of third-party silos.
As a result, organizations are now looking for reliable ways to collect, store, transform, and analyze (or activate) their own first-party data. This is exactly where the modern data stack comes in. It enables organizations to be more self-sufficient and monetize their own data through activation.
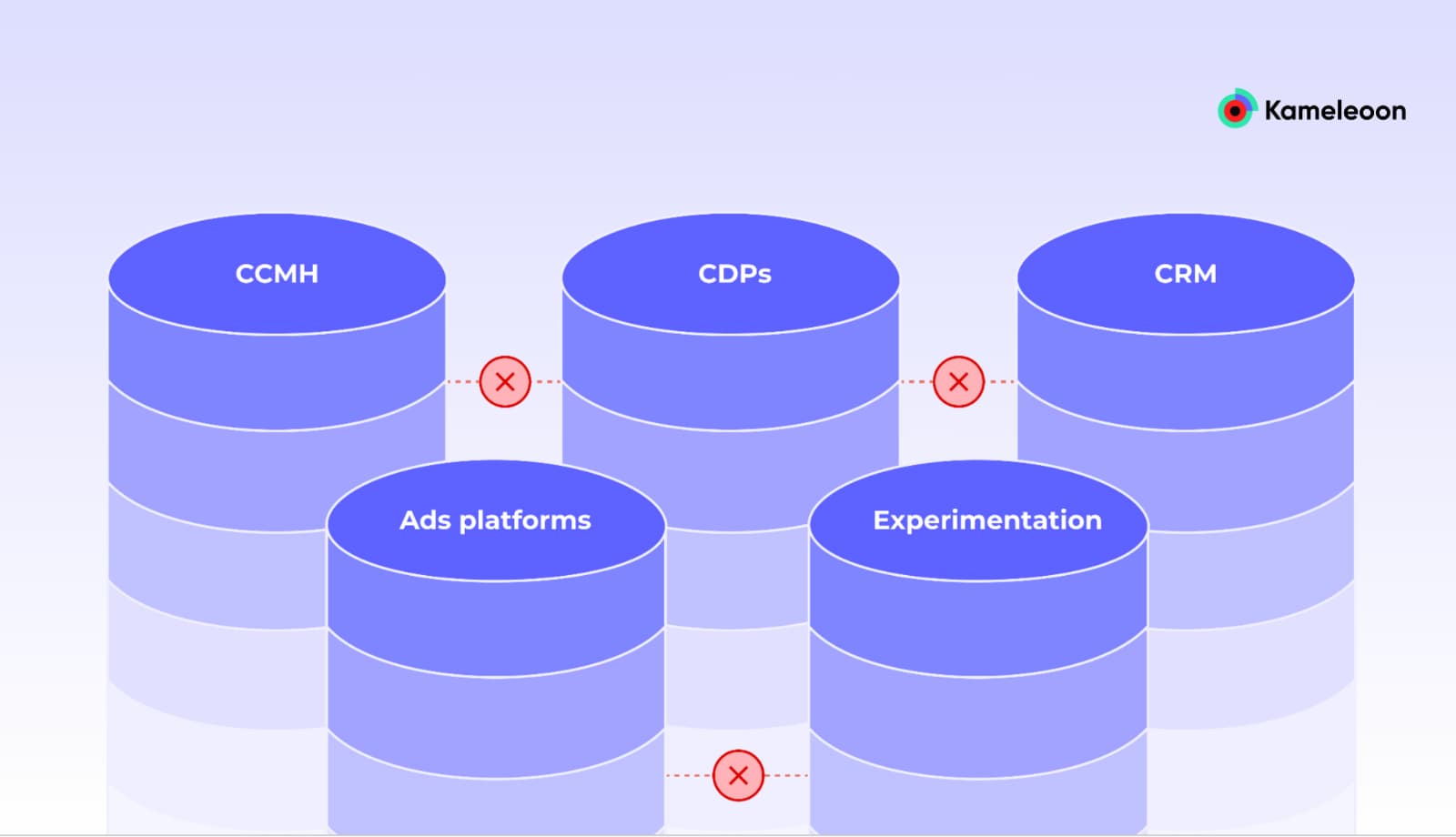
From siloed data to the Data Warehouse as Single Source of Truth (SSOT)
Below is a visual representation of the web of tools before the modern data stack:
Prior to the modern data stack, companies relied mostly on siloed third-party instruments and their integrations. Each tool stored its own data, leading to multiple “sources of truth.” As a result, the interactions between the instruments were limited.
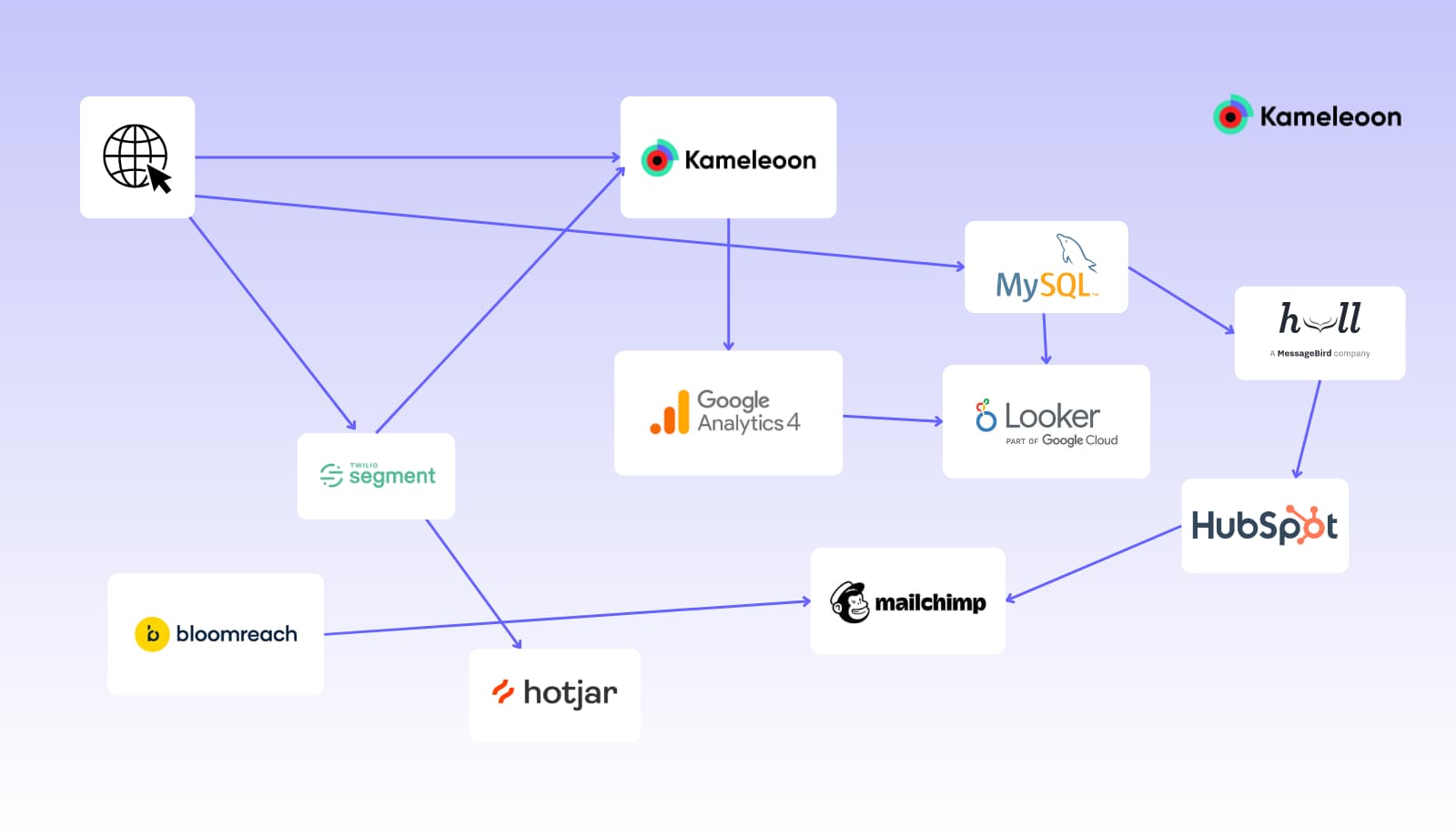
Here is an example of the MDS with some of the most popular tools:
Note that the tools are duplicated to show different options. Most of the time organizations use one instrument for each action.
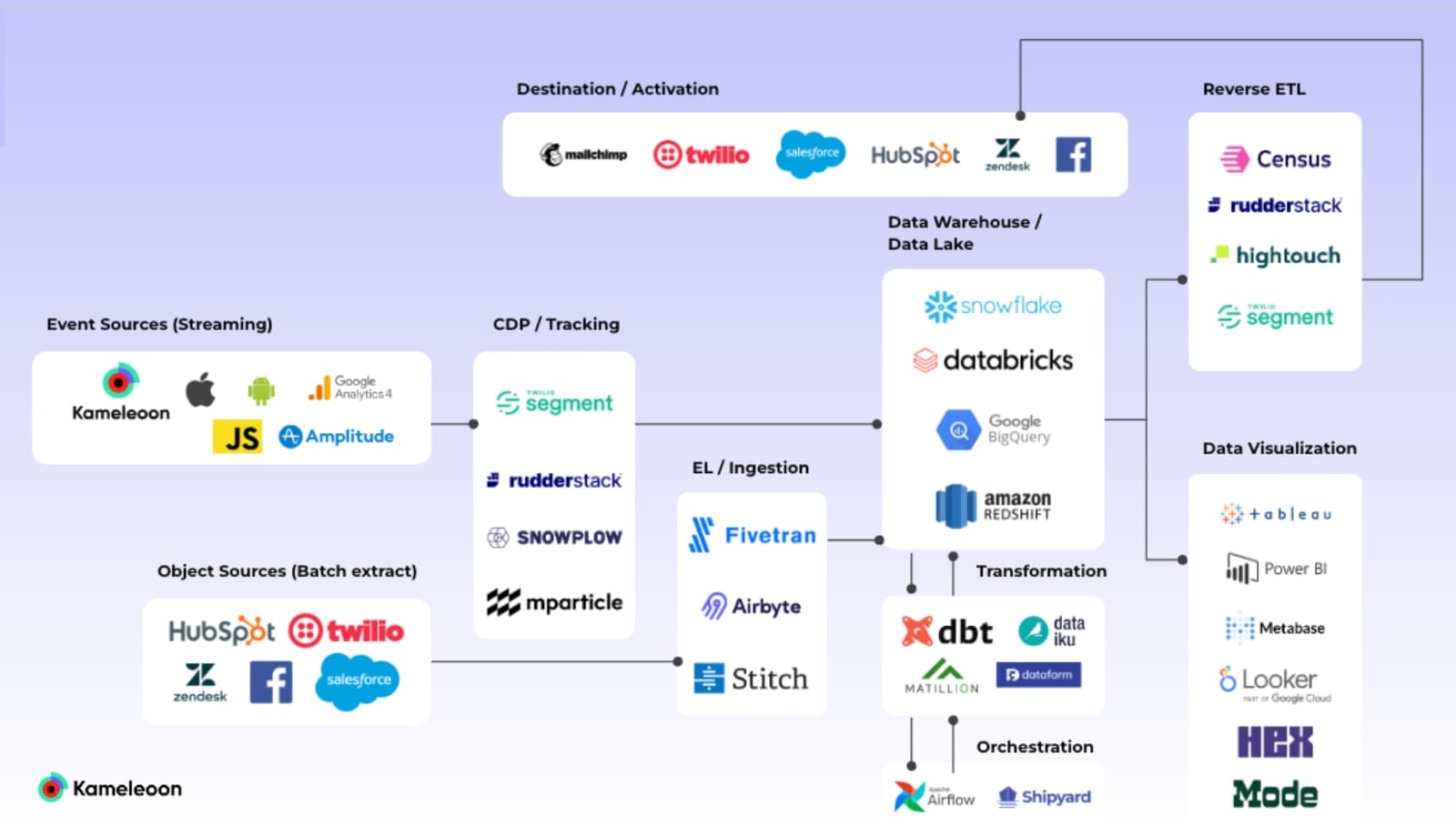
How the modern data stack works
In a data warehouse or lakehouse, everything is built around cloud storage and computation. This allows teams across marketing, sales, finance, customer success, and IT to merge data.
A schematic representation of the flow of data through the modern data stack.
These systems consist of:
- Capturing events from data sources such as apps, websites, etc.
- Ingesting the data via your storage system
- Processing the data so it can be transformed for business intelligence purposes or activation (ie. send it to a marketing tool for activation such as sending an email, displaying a personalization, etc.)
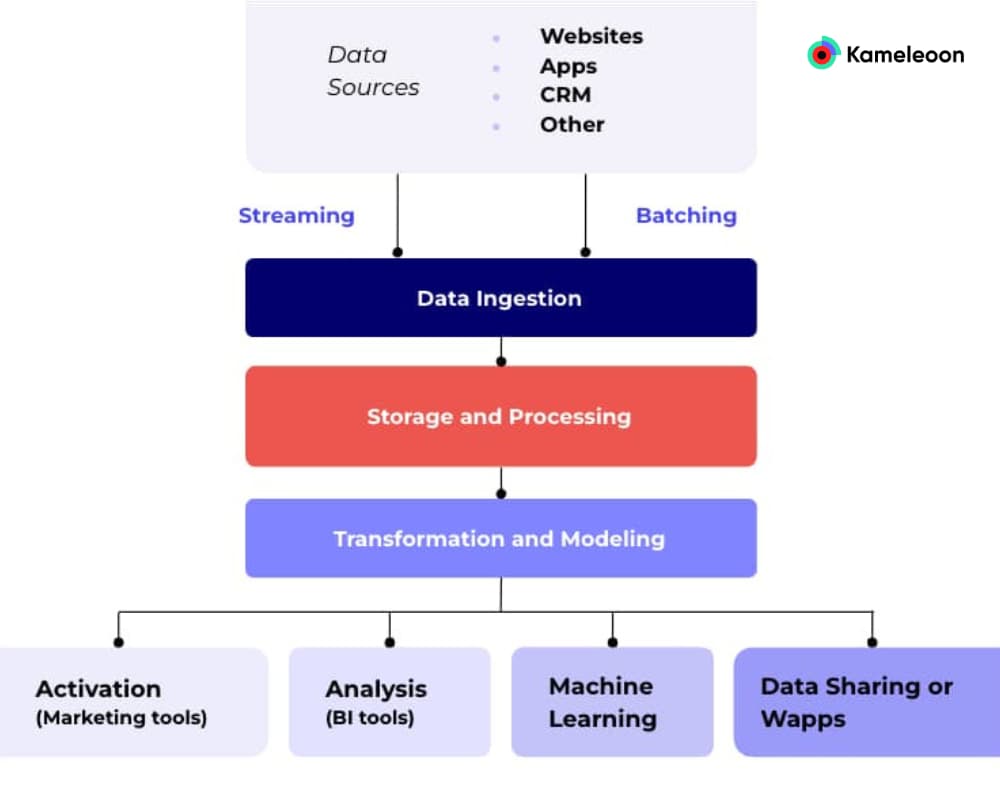
Google and the modern data stack
As mentioned, GA4 is limited in terms of reporting capabilities. Teams are often forced to push data to BigQuery (Google’s Data Warehouse) and eventually to Looker (Google’s visualization studio) to perform advanced analysis.
This is just one application of the modern data stack used by Google:
- Data is passed from an event source to GA4
- The data is then passed downstream to BigQuery (to be processed or transformed)
- Then it is sent to Looker for visualization and in-depth analysis
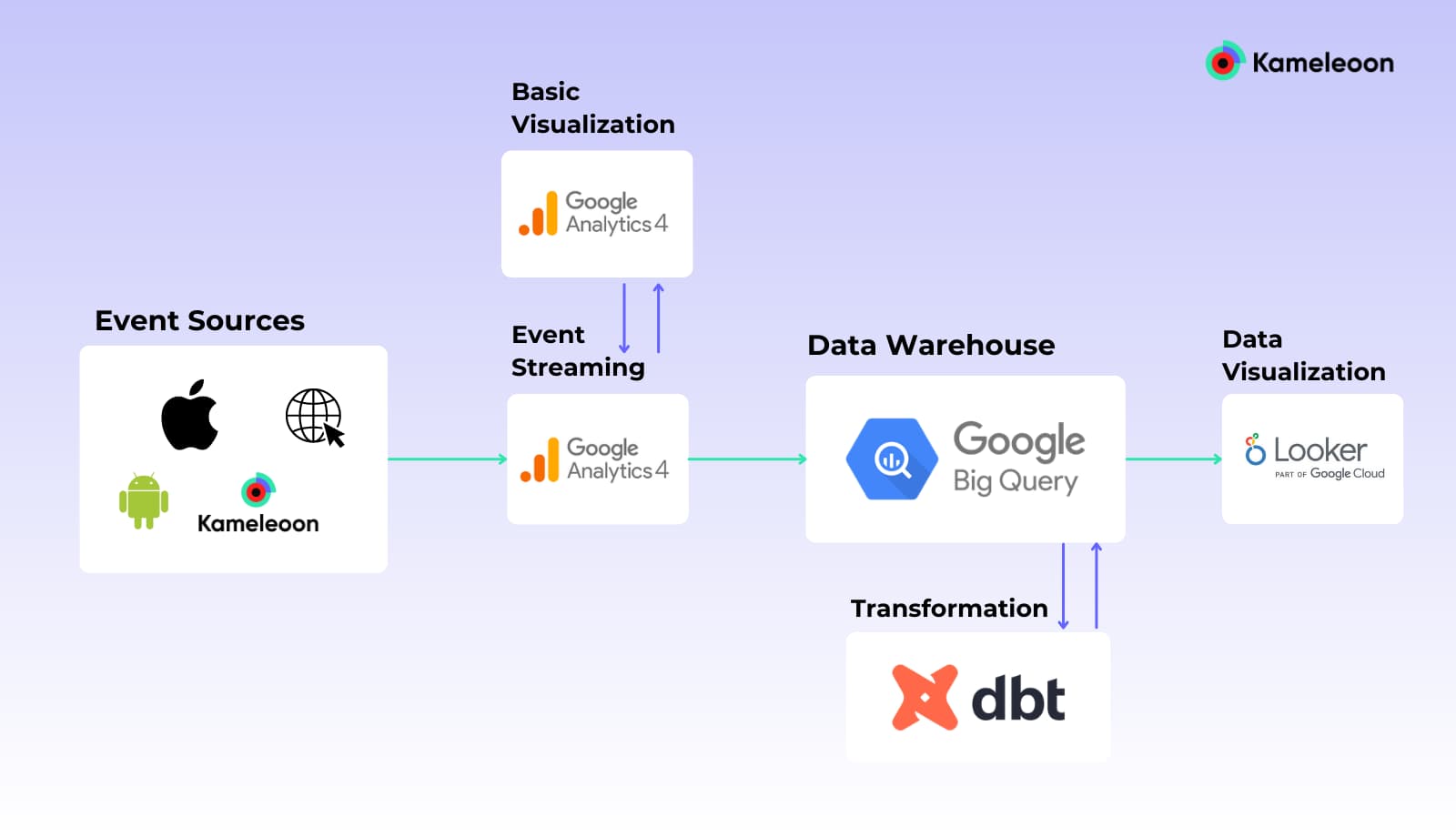
This image is a simplified representation of the process described above. ETL, CDP, Data Governance, and Quality are not represented. GA4 is also duplicated to highlight the possibilities of visualizations before BigQuery’s ingestion and after.
Google’s application of the modern data stack allows organizations to build the whole ecosystem around a Single Source Of Truth (SSOT) and get rid of most of the GA4/GO sunset limitations.
However, this has several drawbacks:
Increased complexity
- The setup is long and requires a lot of resources.
- SQL is compulsory for any advanced reporting.
- Marketers and non-technical roles can’t proceed without Data Engineers and Analysts.
Additional Costs
- Google's approach locks you into its ecosystem.
- Running reports with BigQuery and Looker can cost thousands of dollars per month without proper workflow optimization.1
Experimentation becomes more challenging
- As Google Optimize phases out, there will no longer be a seamless integration between GA4 and testing tools. Tests must run on one tool and the results must be analyzed in GA4 (or in your experimentation tool).
- GA4 uses ‘Audiences’ for reporting and analysis. Free Audiences are limited to 50 and are often deleted when the test is stopped, after which you must rely on BigQuery (which comes with additional costs) or eventually ‘Explore’ 2 with its own set of constraints.
It offers alternatives in a high-competition ecosystem
- The modern data stack consists of a galaxy of tools, some of which are open source. Google's move to the GA4 + BigQuery + Looker stack forces users to embrace the MDS. However, they might be tempted to build their stack around other tools outside of Google’s ecosystem. For instance, Segment + Amplitude + Snowflake for the packaged/closed source or Snowplow + Airbyte + Spark + dbt for the open source fans.
- There is also an option to rely exclusively on product analytics solutions such as Amplitude, Mixpanel, Heap, or June.
Alternatives: Data warehouse or product analytics as a Single Source Of Truth
Data warehouse along with product analytics
To leverage the full capabilities of GA4, it is necessary to run it within a set of integrated tools — GA4, BigQuery, and Looker. Because building this tech stack is complex and costly, it’s important to consider all available alternatives, such as Snowflake or Amplitude, before committing to Google’s MDS.
The heart of the system is the Data Warehouse (DWH). The DWH industry is monopolized by tech giants offering incredibly powerful instruments.
If you plan to store a large amount of raw data and build a machine learning model on it, then Databricks is a perfect fit. If you want a user-friendly solution for business intelligence, Snowflake is one of the best options. All legacy companies — Amazon Redshift, Microsoft Azure, and even IBM’s Db2 — want their share of the market, which is expected to reach $48 billion by 2028! 3
Now you may be wondering, why not capture events via product analytics tools such as Mixpanel, Amplitude, or Heap? They all offer SDKs allowing you to capture events and build reports. Their reporting capabilities stand above GA4's. They offer more granular insights, better funnel segmentation, and simplified collaboration.4,5 When it comes to understanding how users behave and interact with your product, these tools are exceptional.
Furthermore, if your analysis requires data enrichment (with data coming from different departments such as sales or finance) or complex queries for advanced analysis, then data visualization tools are available as supplementary. Tableau and Power BI are longstanding players in the industry, with new tools popping up regularly (such as Mode).
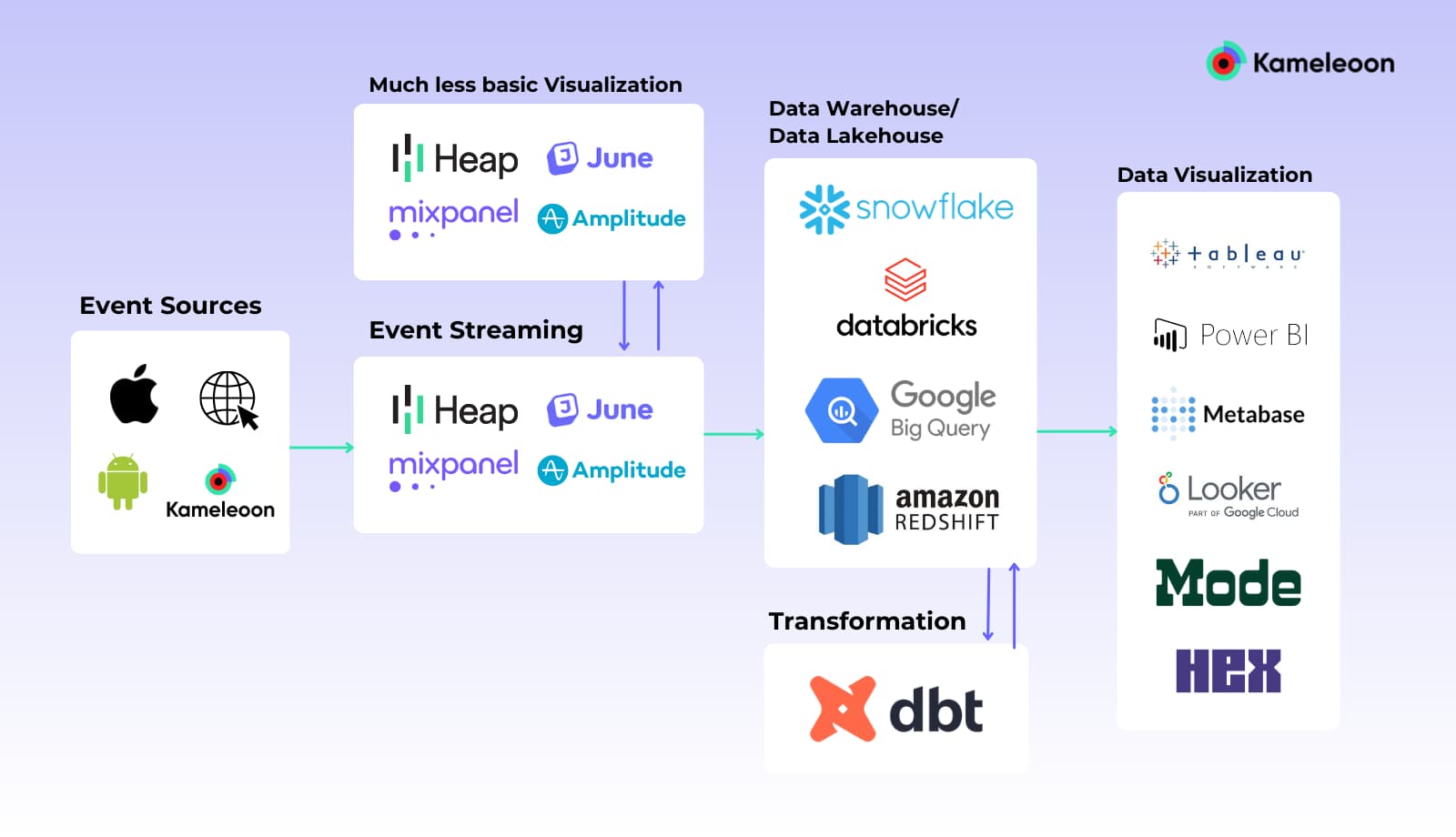
Note: this is a simplified representation - ETL, CDP, Data Governance and Quality are not represented and PA tools are duplicated to highlight the possibilities of visualizations before DWH’s ingestion and after.
However, this is not the best approach. Performing analysis within your product analytics tool and your BI instrument (based on events stored in the DWH) goes against the best practice of having a Single Source of Truth (SSOT). That’s because by nature, analysis in two separate tools implies the existence of two sources of truth. If you were to perform the same query on two different systems, you would obtain two different results. Even so, this approach offers one important advantage: the ability to perform most of the analysis without a Data Analyst or Data Scientist. This capability is key, as these roles tend to be scarce and in high demand at most organizations.
Product analytics only
Some organizations rely exclusively on their product analytics solution as their SSOT without using the data stored in their DWH or even implementing a DWH altogether.
I expect this practice will become less and less common over the years, particularly for enterprises and SMEs.
In Segment’s CDP report (2023), Snowflake is reported as the 5th Fastest Growing App, and DWH is the second most Popular App Category within Twilio Segment Platform. The report goes on to say that, “53% of Twilio Segment customers now connect to a warehouse destination.” 6
This is only the beginning, as even in these uncertain times, “56% of Data Leaders are increasing their budgets.” 7
Finally, there may be a third and final option to run your product analytics solution natively within a DWH. This would reduce the never-ending conflict between BI and product analytics. This trend is just emerging, as spotted in a report by Data Beats, however, it’s worth paying attention to.
The modern data stack is here to stay
The rise of the modern data stack represents a major shift in the way organizations approach data, with the potential to transform the industry in profound ways. Google Analytics’ evolution to a 4th iteration (fully integrable in the modern data stack) and the sunset of Google Optimize are two small events that represent this paradigm shift coming into full effect.
Most of the emerging products and tools coming onto the market today will rise around the data warehouse — and we had better be ready.
Check out our latest Think Ahead event, How the Modern Data Stack Powers Experimentation to learn more about the MDS and what it means for your experimentation program.
All views expressed are my own.
Sources:
1https://analyticscanvas.com/costly-mistake-connecting-ga4-bigquery-to-data-studio/
2 https://support.google.com/analytics/answer/7579450?hl=en#zippy=%2Cin-this-article
3https://www.databridgemarketresearch.com/reports/global-data-warehousing-market
4https://amplitude.com/blog/amplitude-vs-ga4-webinar-recap
5https://marketlytics.com/blog/google-analytics-4-vs-mixpanel-comparsion-2023/
6https://segment.com/the-cdp-report/
7https://humansofdata.atlan.com/2023/03/future-of-data-analytics-2023/
8https://databeats.community/p/warehouse-native-product-analytics-netspring#details


