
Ronny Kohavi shares how to accelerate innovation by getting results you can trust
A name synonymous with trustworthy testing, Ronny Kohavi is the former Vice-President and Technical Fellow at Microsoft and Airbnb. Over his 20+ year experimentation career, he’s run thousands of online experiments and has assembled his observations into a best-selling book, Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. He shares his observations through dozens of published pieces, and now offers a course on accelerating innovation with A/B testing.
In this article, based on this interview, Ronny warns of the many pitfalls that experimentation programs fall into when running online tests. He also provides several strategies to overcome these data inaccuracies and obtain trustworthy test results.
Three data accuracy traps and how to avoid them
When running online experiments, getting numbers is easy. Getting numbers you can trust is hard.
Although A/B tests are considered the gold standard of online testing, there are also many factors that can jeopardize test trustworthiness.
Experimenters and organizations that don’t focus on trustworthy test results risk losing revenue and credibility, resulting in a damaged reputation that’s hard to repair.
If this outcome occurs, management, or your clients, can lose confidence in your work. And, organizational buy-in becomes even more challenging, threatening the overall feasibility of your experimentation program and the perceived value of testing.
To prevent these negative outcomes, it's important to get trustworthy, reliable results that propel the organization forward.
To do so, here are the three main actions Ronny suggests you take.
1. Follow the key statistics principles
Design experiments with adequate power
When running any test, there’s always a chance you’ll get faulty results. A test can yield what’s known as a false positive or a false negative.
In A/B testing, a false positive, also called a type I error, happens when you claim there’s a conversion difference that isn’t really there.
In contrast, a false negative, also known as a type II error, occurs when you incorrectly declare there’s no conversion difference when, in fact, there is one.
Either error skews the accuracy of test results, so should be avoided.
Power measures the percentage of time a real effect, or conversion difference between variant(s), will be detected — assuming a difference truly exists.
Essentially, it provides a metric to help you assess how well you’ve managed to avoid a type II error so you don’t incorrectly declare there’s no conversion difference — when in fact, there is one.
The standard level to set power is 0.80 (80%). This amount means you’ll accurately detect a true effect at least 80% of the time.
As such, there's only a 20% chance of missing the effect and ending up with a false negative. A risk worth taking.
The higher the power, the stronger the likelihood of accurately detecting a real effect.
Although increasing power may sound like a great idea, there’s a trade-off.
The greater the power, the larger the sample size needs to be. And, often, the longer the test needs to run.
So, getting adequate power can be tricky, especially for lower traffic sites.
A test is underpowered when the sample is so small the effect, or conversion difference detected, isn't accurate – leading to a type I error (false positive). The lower the power, the more exaggerated the effect may be.
While low-powered tests can achieve statistical significance, the results aren’t to be trusted.
To ensure results are accurate, experimenters need to run adequately powered studies with a large enough sample size.
How large is large enough?
To properly answer this question, a sample size or power calculator should be used AHEAD of running the study.
If sample size or power calculations show you need more traffic than your site receives in a typical 2-6 week testing time frame, you should evaluate whether the test is worth running as the results are likely to be inaccurate.
Don’t peek
Once you’ve confirmed you have a large enough sample size to run an adequately powered study, don’t stop the test before reaching the pre-calculated sample size requirements.
This is known as peeking because you’re “peeking” at the results and may be tempted to prematurely declare the test a winner (or loser) when, in reality, it’s far too early to accurately tell.
For many websites, getting enough traffic takes time. And waiting is hard.
But peeking is a bad practice that can lead you to make money-losing mistakes.
Set a lower alpha
Provided your study is adequately powered, and you don’t prematurely stop the test, you should be in good shape.
However, your test still runs the risk of yielding a type I error (false positive).
Remember, this error occurs when you think you’ve detected a conversion difference that doesn’t really exist.
To lower the risk of a false positive, you can set the cut-off point at which you’re willing to accept the possibility of this error.
This cut-off point is known as significance level alpha. But most people usually just call it significance or refer to it as alpha (denoted α).
Experimenters can choose to set α wherever they want.
The closer it is to 0, the lower the probability of a type I error.
But, it’s a trade-off. Because, the lower α, in turn, the higher the probability of a type II error.
So, it’s a best practice to set α at a happy middle ground. A commonly accepted level used in online testing is 0.05 (α = 0.05).
This level means you accept a 5% (0.05) chance of a type I error, or of incorrectly declaring a conversion difference when there really isn’t one. A calculated risk worth taking.
Interpret the p-value results correctly
However, even if you’ve prudently set α ≤0.05, you’re not out of the woods yet.
Because your findings still may just be the outcome of just random chance or statistical noise.
To be sure they’re not, you next need to measure the probability you’ve detected an effect – assuming there’s actually no real difference between the control and variant(s).
To measure this probability, you need to assign a value known as a probability value, commonly called a p-value.
P-value is an outrageously mis-understood concept. But for a test to be trustworthy, you need to be able to interpret the p-value results correctly.
Doing so is actually quite simple.
When the p-value is less than α (p≤α), it means the chance of detecting the effect is really low.
Because the chance is so low, when an effect is detected, it’s considered an unusual, surprising outcome – one that’s significant and noteworthy.
Therefore, a p-value of ≤0.05 means the result is statistically significant.
The closer the p-value is to 0, the stronger the evidence the conversion difference is real – not just the outcome of random chance or error.
Which, in turn, means you have stronger evidence you’ve really found a winner (or loser).
Use Bayes’ rule to reverse p-values to false-positive risk
However, even if you’ve obtained a statistically significant result, based on a properly-powered study, you can’t fully trust the result. Yet.
That’s because you’ve compromised in accepting a small margin of error – which still gives the very real probability of a false positive or false negative.
However, through a calculation known as Bayes’ Rule, also called Bayes’ Theorem, you can reverse the probability of a false positive – which translates into the real chance of a true positive.
Bayes’ Rule determines the probability of independent events occurring and is calculated through this formula:
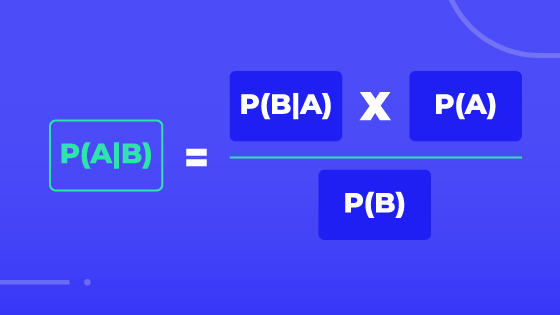
Where:
- P(A|B) is the probability of event A occurring, given event B has occurred
- P(B|A) is the probability of event B occurring, given event A has occurred
- P(A) is the probability of event A
- P(B) is the probability of event B
When you use Bayes Rule to reverse the false positive risk, you know, with greater confidence, you've truly found a real effect.
2. Build in guardrails to check assumptions
Watch for SRM
Yet, while you may have truly accurately detected a real effect, your test results can still be flawed if your data is inaccurate.
Many A/B test results are invalid because of faulty data collection. One of the worst offenders is known as Sample Ratio Mismatch (SRM). SRM occurs when test traffic is distributed differently than the experimental design. For example, in a uniform split design, there is an SRM if one variation receives much more traffic than the other(s).
SRM occurs in about 6-10% of all A/B tests, and invalidates the test results.
There are more than 40 reasons why SRM might occur. Most relate to improper set-up of the test, bugs with randomization, tracking and reporting issues, or the outcome of bots falsely inflating traffic numbers.
Not all of these problems are avoidable, but some are.
To guard against SRM, there are certain measures you should take, including:
- Choose an enterprise-grade experimentation platform that automatically detects and provides alerts if SRM occurs.
- Pay attention to SRM alerts, when they’re provided.
- Filter out problematic traffic segments to diagnose where the SRM issue may have arisen.
- Re-run the test, if necessary.
- Set-up and run A/A tests as a diagnostic tool to prevent against SRM.
Use A/A tests as a diagnostic tool
One of the best ways to validate accuracy is to test the same variant against itself — through something known as an A/A test.
If you’re not completely clear what an A/A test is, don’t fret. A recent survey found 32% of experimenters weren’t sure either.
But the concept is actually quite simple.
An A/A test is exactly as it sounds: a split-test that pits two identical versions against each other. Half of visitors see version 1, the other half version 2.
The trick here is both versions are exactly the same.
It’s slightly counter-intuitive. But, with an A/A test, you’re actually looking to ensure there is no difference in results.
When running an A/A test, if one version emerges with a radically different traffic split, or as a clear winner, you know there’s an issue.
A/A tests can be thought of as a diagnostic tool that can uncover many bugs in your test set-up, including SRM.
They help you validate that you’ve set-up and run the test properly — and that the data coming back is accurate and reliable.
Although A/A tests have been criticized for being traffic and resource-intensive because they can distract from running “real” tests that bring in conversions, they shouldn’t be overlooked.
To make most efficient and effective use of your testing resources, here are some suggested A/A testing approaches:
Start any test with an A/A test before running an A/B test.
Run A/A tests, continually, in the background or offline. You can get 90% of the value of an A/A test by running the test offline.
Keep the A/A test going the same time period as your A/B tests.
A/A tests should be used as a guardrail to ensure data is accurate, identify bugs in the platform, spot outliers that impact results, and raise the trustworthiness of test results.
Avoiding test trustworthiness traps
We all have a natural bias to celebrate positive results and cast-off negative results, but it’s important to look at both with healthy skepticism.
If any test result looks too good to be true, it probably is. Because, according to something known as Twyman’s law, any figure that looks interesting or different is usually wrong.
So, in your own testing, look for big surprises and question them.
What separates good experimentation programs from great ones is taking measures to overcome these three test trustworthiness traps.
To learn more how you can accelerate innovation with trustworthy online experiments, watch the replay of our webinar with Ronny, ‘How to avoid common data accuracy pitfalls,’ or check out the key takeaways from the event. If you’re interested to learn more about how to design, measure and implement trustworthy A/B tests, check out Ronny’s course, ‘Accelerating innovation with A/B testing.’


